
Last week we announced a new version of our AutoClassifier (you can read the announcement here). This release has many new features and capabilities, including the addition of machine learning into the AutoClassifier. There is remarkable power in machine learning, and we’re excited to add this to our products.
The trick has been doing it without sacrificing transparency and control. I’ve been in the industry long enough that this is the fourth auto-classification product I have brought to the market, and I’ve seen many sophisticated techniques fail because they are “black-box” algorithms that you can’t understand or control. What has made our AutoClassifier successful is that you can get going quickly, understand exactly how and why you get the metadata it generates, and control it as precisely as you want. Machine Learning is notoriously opaque, so we are introducing it in a controllable way.
Combining Rules-based and Machine Learning in a Single Product
We’ve kept our rules-based classification engine as the heart of the AutoClassifier, and added additional modules. In particular, we’ve added:
- Semantic Entity Extraction: a new machine learning based software module that recognizes sequences of words which are the names of things, such as people and company names, or gene and protein names. It ships with pre-trained recognizers for people, places, and organizations, but it is trainable for a wide variety of additional entities.
- Integrated Smart Pipeline: allows you to apply different text analytic techniques in any combination. For example, you might do clustering based on semantically extracted concepts, or auto-tagging using a set of classification rules, and then link in associated data for tags that exceed a specified confidence threshold.
Our AutoClassifier now has multiple text analytics capabilities that can be combined in many different ways. Its overall function – creating metadata – is the same, but you can now combine rules-based and machine-learning approaches to provide consistent, high-quality metadata. Organizations can use the resulting metadata to improve findability, discover new insights, and ensure compliance.
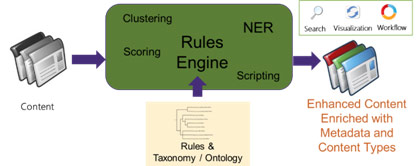 We reached the conclusion at BA Insight that hybrid solutions give the most flexibility, and the best results, which is what prompted us to come up with this new release of the AutoClassifier. We allow our customers to apply the best technique, or to combine techniques in innovative ways when that’s needed. Our customers benefit from leading-edge text analytics technology, and also from the flexibility to apply our product in different ways to different content or different applications.
We reached the conclusion at BA Insight that hybrid solutions give the most flexibility, and the best results, which is what prompted us to come up with this new release of the AutoClassifier. We allow our customers to apply the best technique, or to combine techniques in innovative ways when that’s needed. Our customers benefit from leading-edge text analytics technology, and also from the flexibility to apply our product in different ways to different content or different applications.
Machine Learning versus Rules-Based Classification
– the End of a Debate
Back in November I did a session at Taxonomy Bootcamp explaining Rules-Based and Machine Learning-Based approaches to AutoClassification (you can download the slides from slideshare). There’s been a battle in the industry between these techniques, and there are pros and cons to each, but neither technique is best for everything. Here’s a high level summary of the pros and cons from my talk:

Which is better? Neither, and both. If you are just getting started, it’s simpler to use rules. If you are looking for the most extensive coverage in a wide domain, you’ll want to use some machine learning. And if you want the best possible results, it turns out that a hybrid combination of both is the winner.
This reminds me of a similar ”battle” 15 years ago between statistical and linguistic approaches to search. In the end, the best answer was to use both, and all modern search engines combine statistics and linguistics internally.
I believe we’ve been able to make a single product in the AutoClassifier that allows our customers unprecedented power without losing the simplicity that we are often complimented for. Our customers have told us that we made it simple to combine techniques, and easy to understand.
Other Notable Updates in AutoClassifier V3
In addition to the change highlighted above, there are many new features in AutoClassifier V3:
- Scripting: supports VBscript or C# plugins to process the output of rules procedurally, so that you can control any aspect of the processing you want.
- Scoring and Thresholding: is now visible in the testbed, extensible by scripting, and extended to cover new scenarios.
- Tag History and Auditing Reports: have been added to enhance taxonomy management.
- SharePoint Document Sets: can now be classified as a single entity
We’ll continue to invest in the AutoClassifier, and now that we have an ability to plug in different modules we can do some amazing things. I expect that our customers will also come up with ideas and innovative solutions as well. Adding machine learning under the hood is exciting, and a hybrid combination of techniques provides the best of both worlds.
Here Are Some Frequently Asked Questions About AutoClassifier:
Have you added support for SharePoint 2016?
Yes, AutoClassifier V3 supports O365, SharePoint 2013 and SharePoint 2016. Hybrid SharePoint configurations are also supported.
What kind of content can I process with the AutoClassifier?
If you can crawl it, you can process it. Combining the AutoClassifier with our connectors provides processing of content from over 60 different systems.
Can I upgrade from previous versions of the AutoClassifier?
Yes. Follow the online documentation in the customer portal to upgrade, and contact customer support with any questions.
Do I need a taxonomy? Where can I get one?
Even if you use machine learning, regular expression matching, or other modules that aren’t taxonomy based, we recommend starting with one or more core taxonomies and rule sets and then add in the other techniques.
- In most cases, you’ll find you already have a taxonomy in house.
- You can use a simple list as a taxonomy – for example, your product names and/or project names.
- You can often download free taxonomies (taxonomy warehouse and BARTOC.org are two good sources).
- Commercial taxonomies are also available from our partner WAND.
Any of these should be taken as a starting point – expect to tailor and maintain these over time to adapt them to your specific needs. We recommend using multiple simpler taxonomies rather than one giant one. You can often work with a simple “enterprise-wide” taxonomy that’s applied to all content and then apply different department-specific taxonomies to different sets of content.